Select your language
")
")
Concours text mining AIforGood : TETIS est 2nd
L'équipe text mining de TETIS est arrivée 2ème au concours "GeoAI Challenge" d’AIforGood (ONU)
Descriptif :
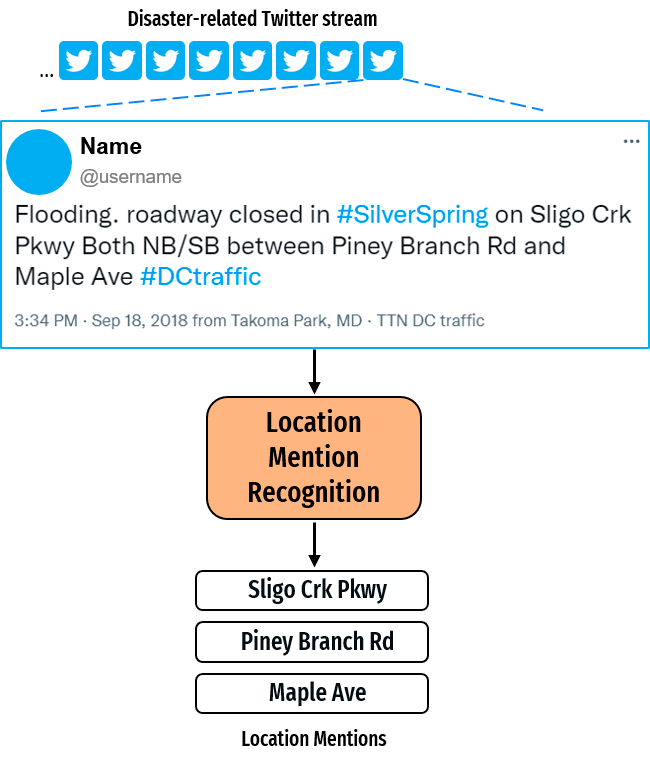
Lorsqu’une catastrophe a lieu, les personnes impactées et celles qui observent les évènements partagent des informations utiles aux services d’urgence et de protection civile à travers les réseaux sociaux comme Twitter. Cependant, afin de mieux suivre les évolutions de ces situations, ces informations doivent être géolocalisées afin d’être exploitables pour la gestion de crises.
C’est pourquoi, la plateforme numérique AI for Good, de l’ONU, a proposé le défi suivant : « Location Mention Recognition from Social Media Crisis-related Text ». Ce challenge a pour objectif de détecter les mentions de lieux dans les tweets émis lors de crises (Inondations, incendies, tremblements de Terre, …).
L’information spatiale issue du langage naturel est un domaine de recherche de l’équipe Text Mining de TETIS.
Il était alors intéressant de pouvoir confronter nos approches avec celles de cette communauté. Après avoir analysé les données et testé les approches de référence (baselines) du concours, nous avons ré-entraîné une dizaine de modèles de langue (des modèles d’apprentissage profond basés sur les architectures dites « transformers »), en appliquant différentes stratégies de sélection des valeurs des hyperparamètres ainsi que des augmentations de données.
Après avoir identifié le modèle le plus performant, nous l’avons mis à disposition de la communauté (https://huggingface.co/rdecoupes/tetis-geochallenge) ainsi que nos post-traitement (https://github.com/ITU-GeoAI-Challenge/Tetis-Text-Mining).
C’est pourquoi, la plateforme numérique AI for Good, de l’ONU, a proposé le défi suivant : « Location Mention Recognition from Social Media Crisis-related Text ». Ce challenge a pour objectif de détecter les mentions de lieux dans les tweets émis lors de crises (Inondations, incendies, tremblements de Terre, …).
L’information spatiale issue du langage naturel est un domaine de recherche de l’équipe Text Mining de TETIS.
Il était alors intéressant de pouvoir confronter nos approches avec celles de cette communauté. Après avoir analysé les données et testé les approches de référence (baselines) du concours, nous avons ré-entraîné une dizaine de modèles de langue (des modèles d’apprentissage profond basés sur les architectures dites « transformers »), en appliquant différentes stratégies de sélection des valeurs des hyperparamètres ainsi que des augmentations de données.
Après avoir identifié le modèle le plus performant, nous l’avons mis à disposition de la communauté (https://huggingface.co/rdecoupes/tetis-geochallenge) ainsi que nos post-traitement (https://github.com/ITU-GeoAI-Challenge/Tetis-Text-Mining).
Notre équipe a finalement obtenu la 2ème place de ce concours lors de la cérémonie de clôture de l’évènement qui s’est déroulé le 12 décembre en ligne (avec une rediffusion en direct sur Youtube).
Nous n’étions officiellement que 3 inscrits de l’UMR au Challenge : Nejat Arinik, Roberto Interdonato et Rémy Decoupes mais c’est grâce à l’ensemble de l’équipe que nous avons obtenu ces bons résultats.
Nous n’étions officiellement que 3 inscrits de l’UMR au Challenge : Nejat Arinik, Roberto Interdonato et Rémy Decoupes mais c’est grâce à l’ensemble de l’équipe que nous avons obtenu ces bons résultats.
Dernières actualités
-
 02 December 2025
02 December 2025Prix de la meilleure présentation au BMVC 2025
-
 02 December 2025
02 December 2025Veille en épidémiosurveillance
-
 02 December 2025
02 December 2025Publication dans la revue Machine Learning