Sélectionnez votre langue
")
")
Une méthode pour mesurer les inégalités géographiques des grands modèles d’intelligence artificielle.
Publication dans la revue Machine Learning
Alors que les biais sociaux des modèles de langage sont de plus en plus étudiés, la dimension géographique restait largement inexplorée. Plusieurs chercheurs de l’UMR TETIS ont mis en évidence des déséquilibres majeurs entre régions du monde, avec des conséquences directes pour des applications sensibles comme la gestion de crise.
Dans un article récemment publié dans la revue Machine Learning, cinq chercheurs de l’UMR TETIS proposent une évaluation systématique des biais géographiques présents dans les modèles de langage (LMs).
Les auteurs ont cherché à déterminer si ces modèles représentent équitablement l’ensemble des régions du monde ou s’ils privilégient certaines zones géographiques au détriment d’autres.
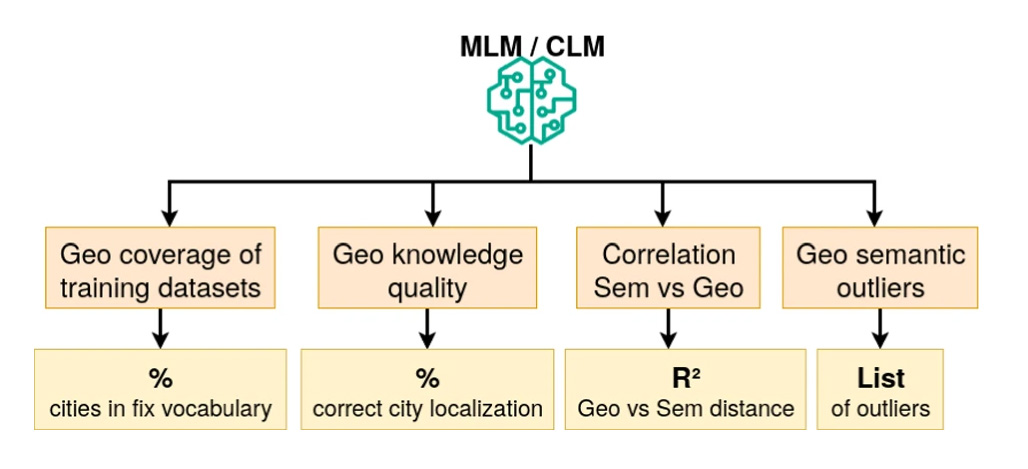
Pour cela, un cadre original d’analyse a été introduit reposant sur quatre indicateurs complémentaires : l’analyse des tokenizers pour estimer la couverture géographique des données d’entraînement, l’évaluation des connaissances géographiques de base, l'analyse de corrélation entre distance sémantique et distance géographique ainsi que la cartographie des distorsions géographiques.
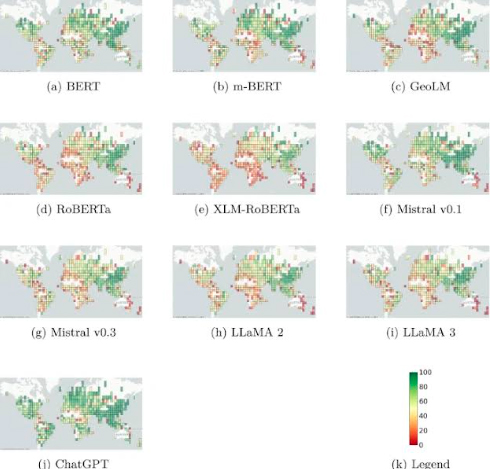
Ce protocole a été appliqué à dix modèles de langage largement utilisés, incluant des architectures encodeur et décodeur. Les résultats montrent une surreprésentation systématique des pays occidentaux et une sous-représentation marquée de nombreuses régions d’Afrique, d’Europe de l’Est et du Moyen-Orient. Ces déséquilibres se traduisent par des écarts mesurables de performance selon les zones géographiques.
L’étude met également en évidence l’impact concret de ces biais sur des tâches applicatives, notamment en réponse aux crises et catastrophes naturelles. Les régions les plus vulnérables sont souvent celles pour lesquelles les modèles sont les moins performants, soulignant un enjeu majeur d’équité dans le développement de l’intelligence artificielle à l’échelle mondiale.
Rémy Decoupes et Maguelonne Teisseire (Inrae), Roberto Interdonato, Mathieu Roche et Sarah Valentin (Cirad) ont conjugué leurs expertises en science des données, traitement automatique du langage et intelligence artificielle pour mener à bien cette publication.
Dernières actualités
-
 2 décembre 2025
2 décembre 2025Prix de la meilleure présentation au BMVC 2025
-
 2 décembre 2025
2 décembre 2025Veille en épidémiosurveillance
-
 2 décembre 2025
2 décembre 2025Publication dans la revue Machine Learning